weekend @evo__hq activities: given the recent sovereign-AI narrative (amidst anthropic's fable pullback), i wanted to see if evo could help make some of the indian models we have better in whatever way.
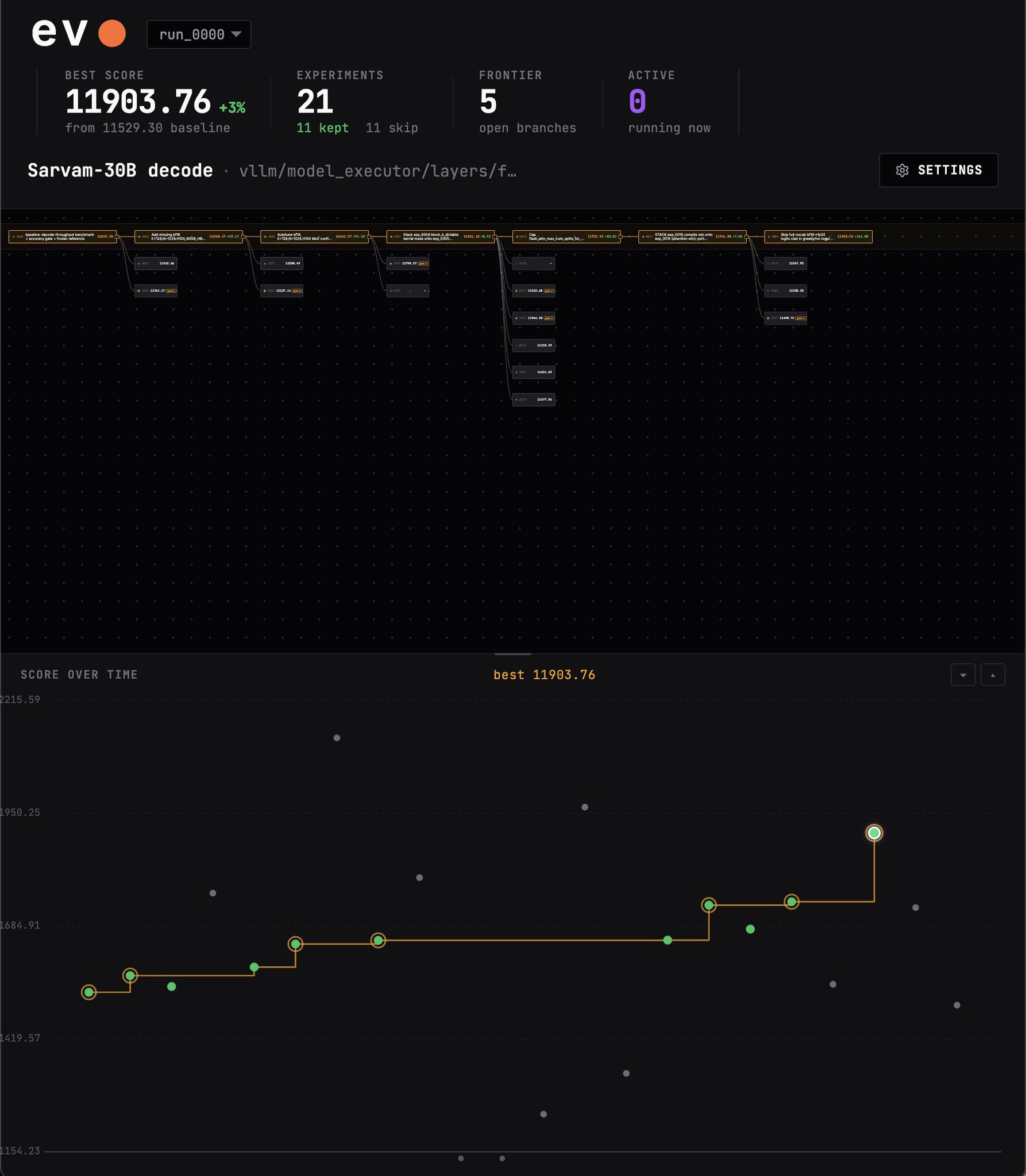
so i kicked off an autoresearch run on evo to see if @SarvamAI's 30B decode throughput could be improved, at bf16, on a single H100.
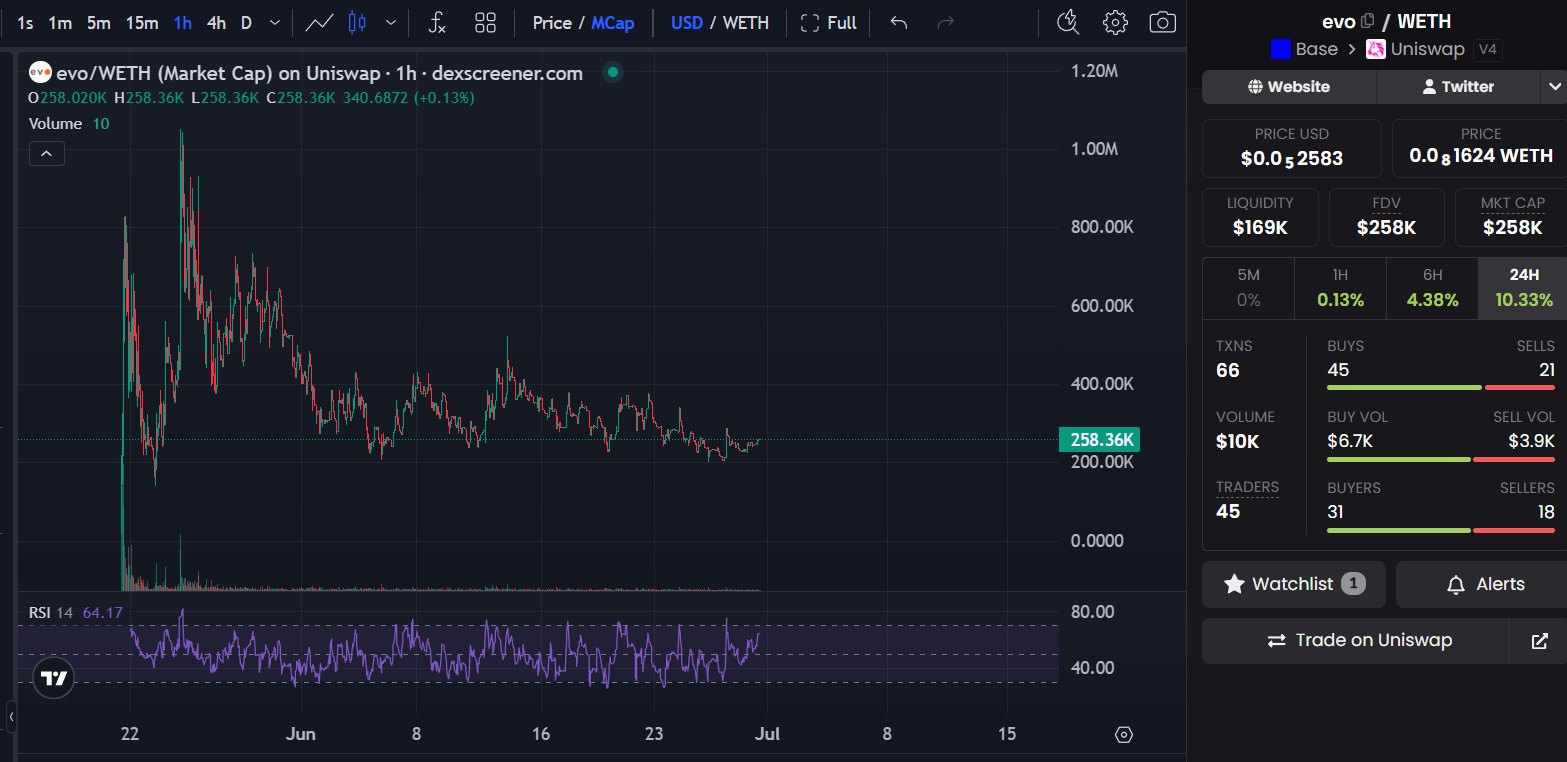
currently 10+ hours in. so far, evo seems to have found ~3% improvement.
the metric is geometric mean tok/s across batch sizes 64 / 128 / 256, measuring steady-state decode only. prefill is timed out, so this is purely per-token decode rate on a fixed workload.
evo also ensures that anything that got faster by changing outputs, lowering precision, or messing with MoE routing was rejected by the accuracy gate.
the gate compares each candidate against a frozen baseline on both next-token distributions and actual decoded tokens. if argmax agreement or logprob drift moves meaningfully, the change is rejected, even if it is faster.
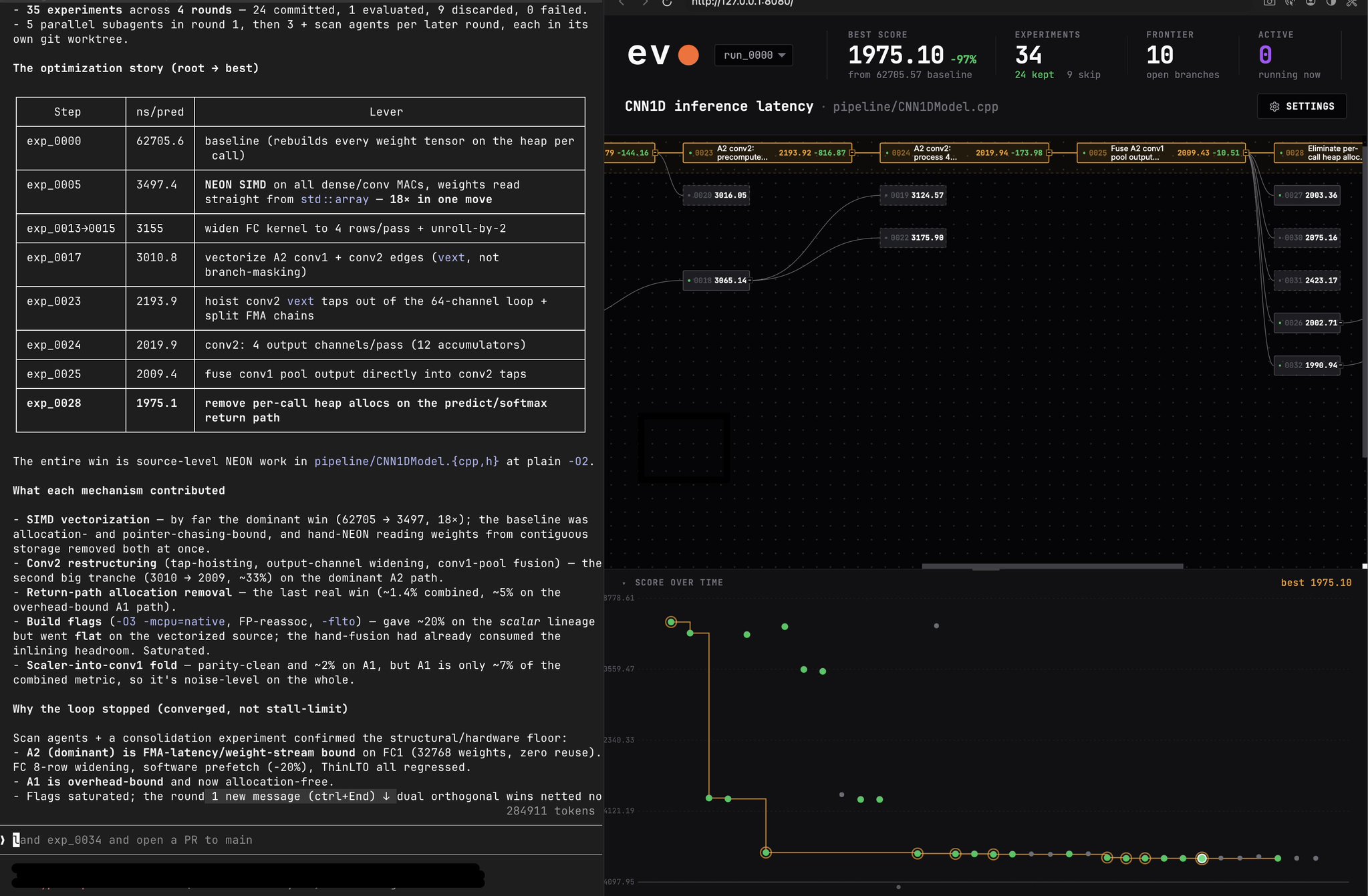
very imp caveat: these are experiment-harness