

感到 @EVO__HQ 将强力反转。
我们最近从开发者那里得到了一些好消息。
$EVO 符合自我提升代理的叙事。
它为代理创建自动循环,以找到在任务上获得最大输出的最佳方式。
我还看到与 @sibyl_labs_ 的强大协同可能,因为所有这些循环都需要强大的记忆检索层。
(用于节省代币和提高准确性)


 7.4K @Jim_buildr
7.4K @Jim_buildr 感到 @EVO__HQ 将强力反转。
我们最近从开发者那里得到了一些好消息。
$EVO 符合自我提升代理的叙事。
它为代理创建自动循环,以找到在任务上获得最大输出的最佳方式。
我还看到与 @sibyl_labs_ 的强大协同可能,因为所有这些循环都需要强大的记忆检索层。
(用于节省代币和提高准确性)
7.4K @Jim_buildr @EVO__HQ CA: base:0x721b072dbb616f29eea73ac004e03fd4e884bba3
 26
26
 7
7
 2.0K
7.4K @Jim_buildr
2.0K
7.4K @Jim_buildr . @EVO__HQ 对非技术人员来说可能相当难以理解
让我来帮你
$EVO 是什么?
一种通过运行数百次实验自动改进软件的 AI 工具
只保留真正有效的部分
证明:
tests just ran on an indian AI model (sarvam 30B)
结果:速度提升 +4.10%,准确性零损失
项目进展
- 2026年4月推出
- 已达 v0.5.3 版
- 1,100+ GitHub 星标
- 平台 Beta 已上线(查看他们的简介)
- 一些知名风险投资公司已关注 @alokbishoyi97
投资逻辑
随着 AI 代理开始自主修改代码,EVO 成为执行+验证工具,以获取最佳产品。
该市场规模相当庞大。
de token use cases are being discussed.
 4.0K @alokbishoyi97
4.0K @alokbishoyi97 周末 @evo__hq 活动:考虑到近期主权 AI 叙事(在 Anthropic 的故事回撤期间),我想看看 EVO 能否以任何方式改进我们的一些印度模型。
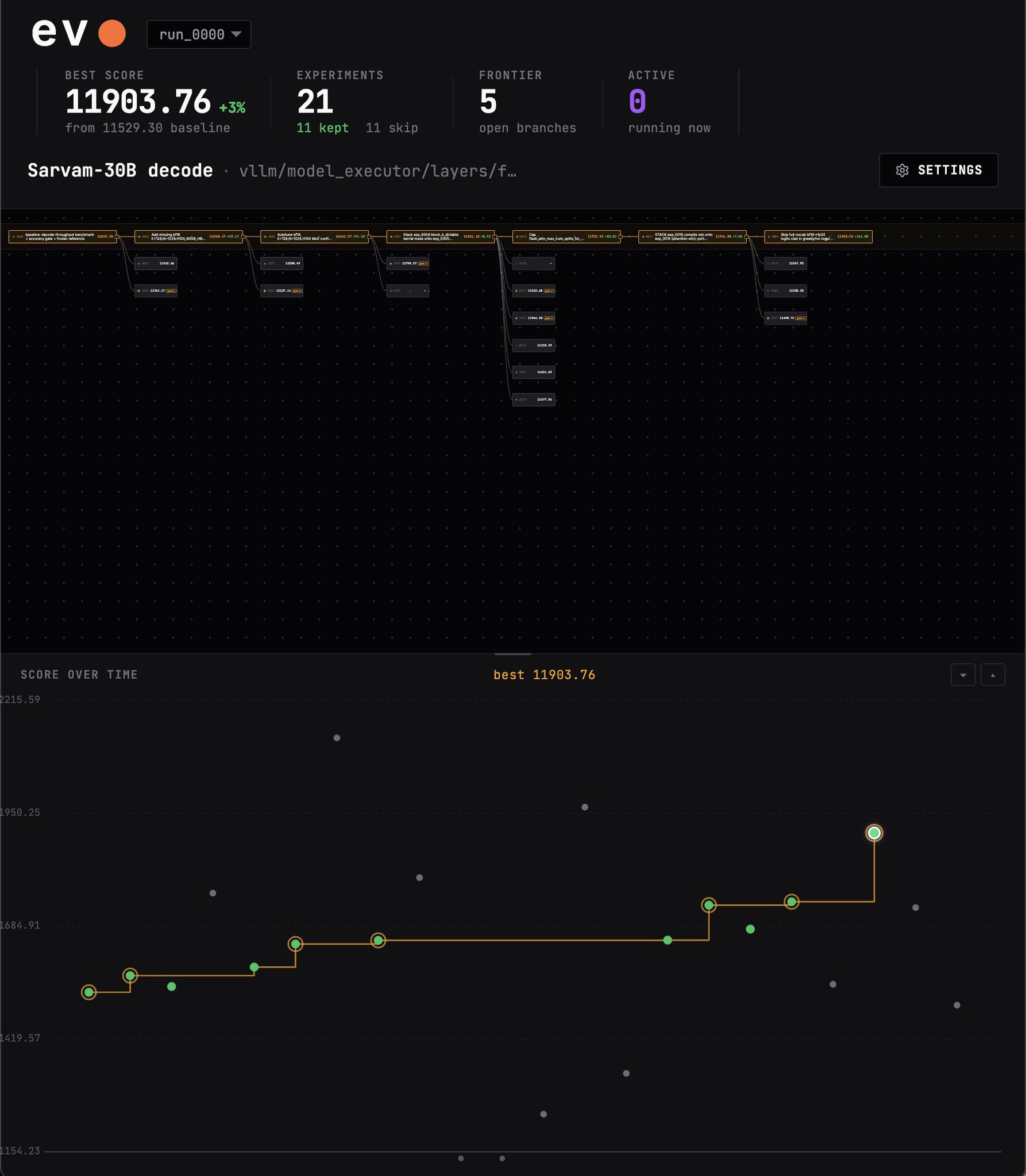
于是我在 EVO 上启动了自动研究运行,以查看 @SarvamAI 的 30B 解码吞吐量在 bf16 模式下、单卡 H100 上是否可以提升。
目前已进行 10+ 小时。到目前为止,EVO 似乎发现约 3% 的提升。
衡量指标为批量大小 64 / 128 / 256 时的几何平均 tok/s,只测量稳态解码。预填充已超时,因此这纯粹是固定工作负载下的每个 token 解码速率。
EVO 还确保任何通过改变输出、降低精度或干扰 MoE 路由而加速的改动都会被准确性门控拒绝。
门控会将每个候选方案与冻结基线在下一个 token 的分布以及实际解码的 token 上进行比较。如果 argmax 一致性或对数概率漂移出现显著变化,即使更快也会被拒绝。
非常重要的提示:这些是实验平台。
 23
9
1.2K
7.4K @Jim_buildr
23
9
1.2K
7.4K @Jim_buildr 我喜欢 @EVO__HQ 正在做的事
他们构建了一个自动改进 AI 代理行为的循环
它自动运行数十个实验并
保留有效的方案
在真实生产代码库上获得 97% 性能提升
已有 10k+ 项目完成优化
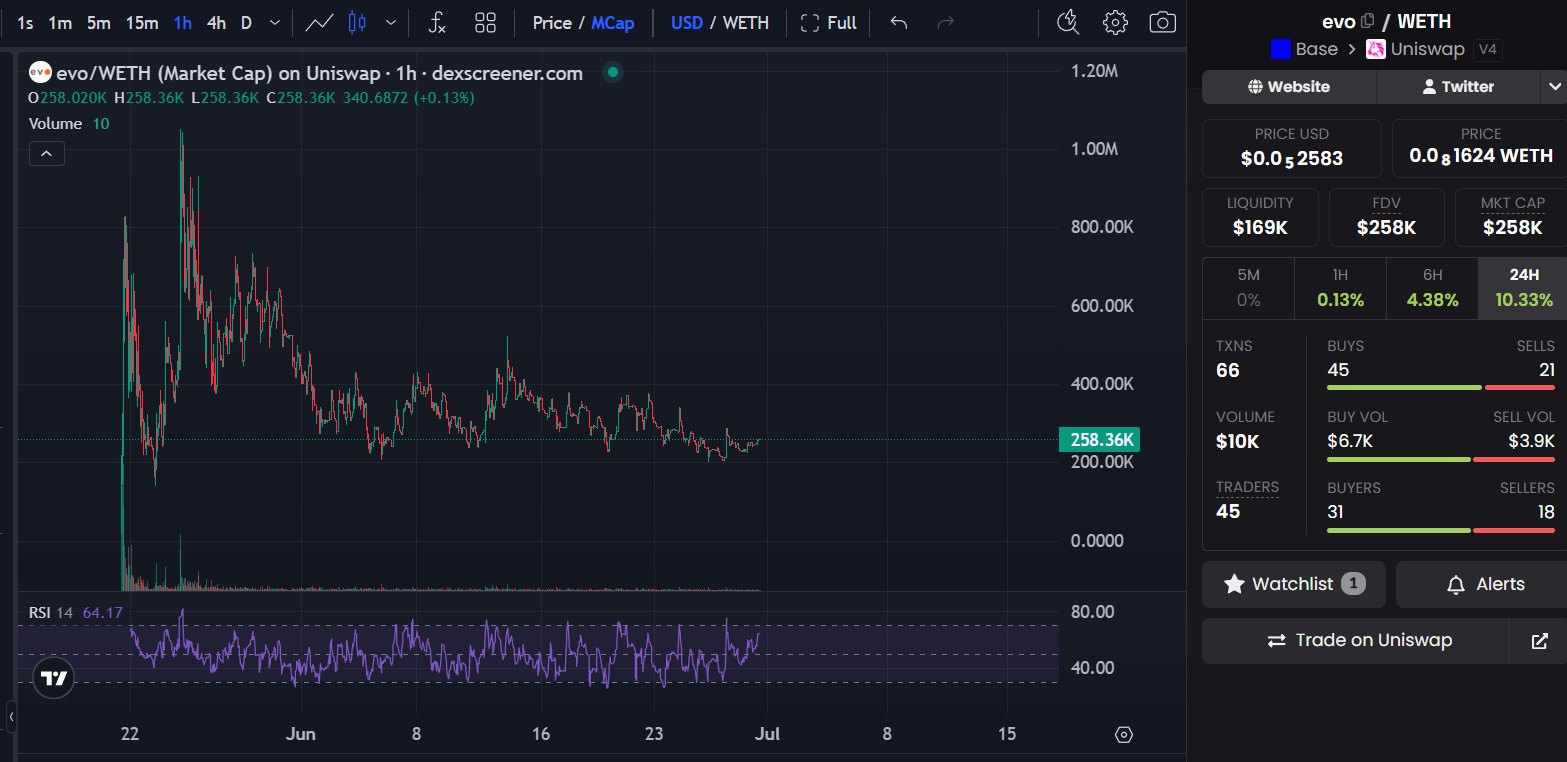
$EVO at 450k mcap
代币实用性仍是未解之谜
但产品是真实的,吸引力不言自明
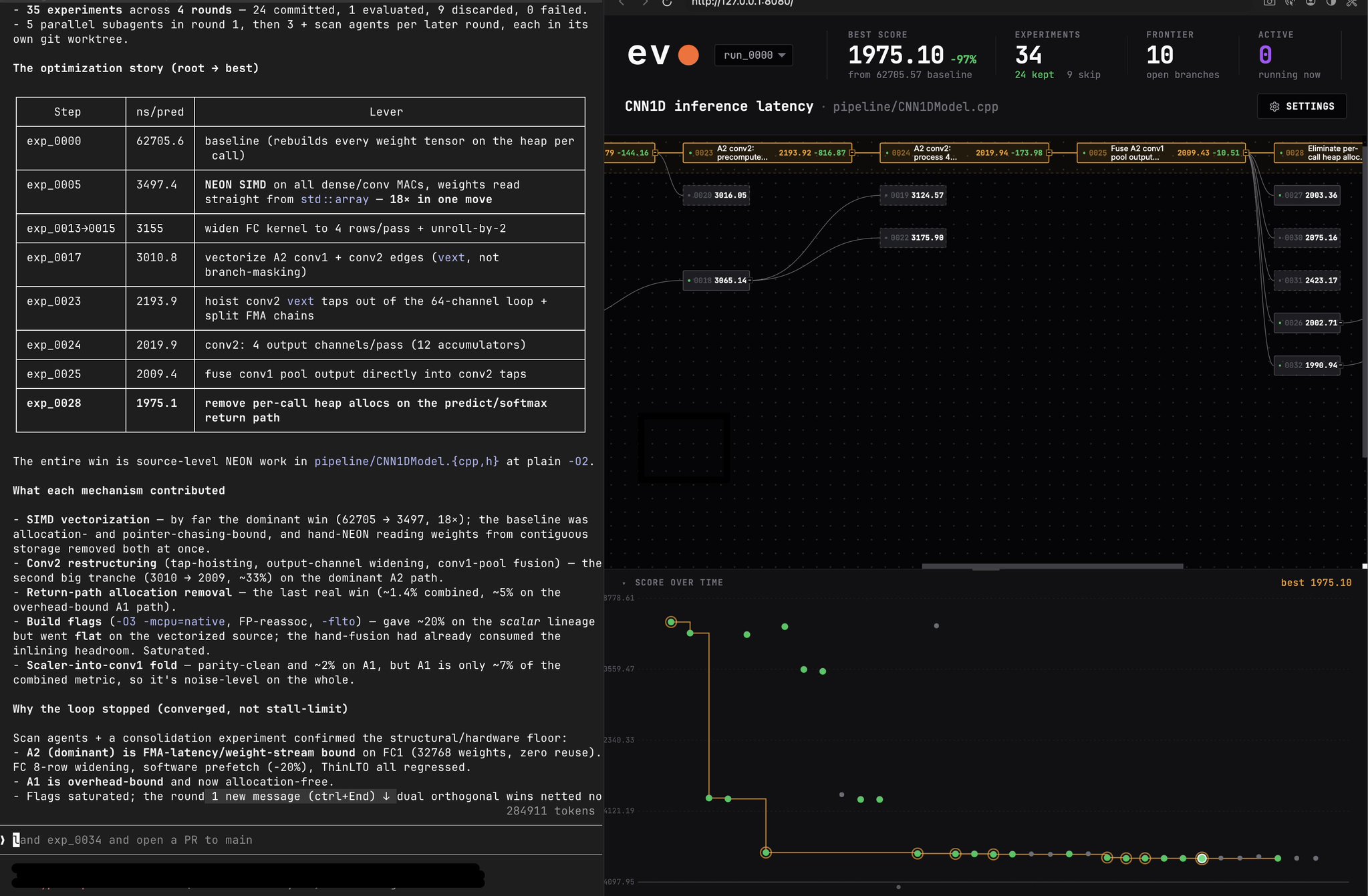
4.0K @alokbishoyi97 分享一次与 @evo__hq 客户的发现通话案例研究
他们的团队拥有一个用于时间序列分析的 CNN1D 流程。EVO 将他们的 C++ 推理路径提升约 30 倍,完全自动化。 https://t.co/fl0m82fsox
 27
11
2.1K
27
11
2.1K




















